
Was ist ein Daten-Hub? – Ein vollständiger Leitfaden
Veröffentlicht: 2021-08-20Das Ökosystem rund um Daten ist ein riesiges Universum. Sie ist so vielfältig, dass jede Organisation, um aus den verfügbaren Daten einen Sinn zu machen, die Implementierung von Systemen zur Verwaltung, Überwachung, Analyse und Interpretation von Daten erfordern würde. Für Unternehmen sind Daten heute ein wichtiger Treibstoff, der die gesamte Entscheidungsfindung innerhalb der Organisation vorantreibt. Doch selbst bei dieser Kritikalität werden Daten in isolierten Systemen gespeichert, was es für die Organisation schwierig macht, die Daten zu analysieren. Einige dieser Daten werden in Data Warehouses oder Data Hubs gespeichert, andere gehen in sogenannten Data Lakes verloren.
- Definieren Sie Data Hub
- Wie funktioniert es?
- Warum DataHub?
- Typen zu kennen
- Unterschied zwischen Data Hub und Data Lake
- Die Vorteile
- Beispiele für Data Hub Technologien
Was ist eine Datendrehscheibe?
Ein Data Hub ist ein modernes Datenspeichersystem, das Unternehmen dabei unterstützt, unternehmensweite Daten zu konsolidieren und zu speichern. Es ermöglicht Unternehmen auch, Daten zur weiteren Analyse in andere Systeme wie Business-Intelligence-Systeme oder KI-Engines zu übertragen. Diejenigen Unternehmen, die Daten in Silos betreiben möchten, sollten verstehen, dass das Vorhandensein von Daten ihren Datenverwaltungsprozess vollständig rationalisieren und den Datenfluss im gesamten Unternehmen glätten wird.
Es gibt mehrere Technologien wie Data Warehousing, Data Science und Data Engineering, die in einer Data Hub-Architektur gipfeln. Mehr als eine Technologie, kann es als Methode betrachtet werden, um die Effektivität bei der Verwaltung von Daten und der Art und Weise, wie die Daten gespeichert werden können, sicherzustellen, um Unternehmen bei der weiteren Verarbeitung zu unterstützen.
Wie funktioniert Data Hub?
Nach der Implementierung muss jeder Benutzer, Bereitstellungspartner oder Betreiber eine Nutzungsvereinbarung unterzeichnen, die ihm die Erlaubnis gibt, Daten sicher an das Data-Hub-Repository zu übertragen. Dies dient dazu, die Vertraulichkeit der Daten zu gewährleisten, auf die Benutzer Zugriff haben. Die Datenübertragung erfolgt über eine sichere und anerkannte Integrationsmethodik.
Die erhobenen Daten werden zentral zur Verfügung gestellt und zur Einheitlichkeit standardisiert. Anschließend wird eine Reihe von Analysen der gesammelten Daten durchgeführt, um aussagekräftige Informationen über Abteilungen, Betriebseinheiten und andere Sektoren hinweg bereitzustellen. Schließlich werden die Daten zur weiteren Nutzung an die jeweiligen Systeme zurückgesendet. Dies wird in einem vereinfachten Diagramm erklärt, wie unten erwähnt
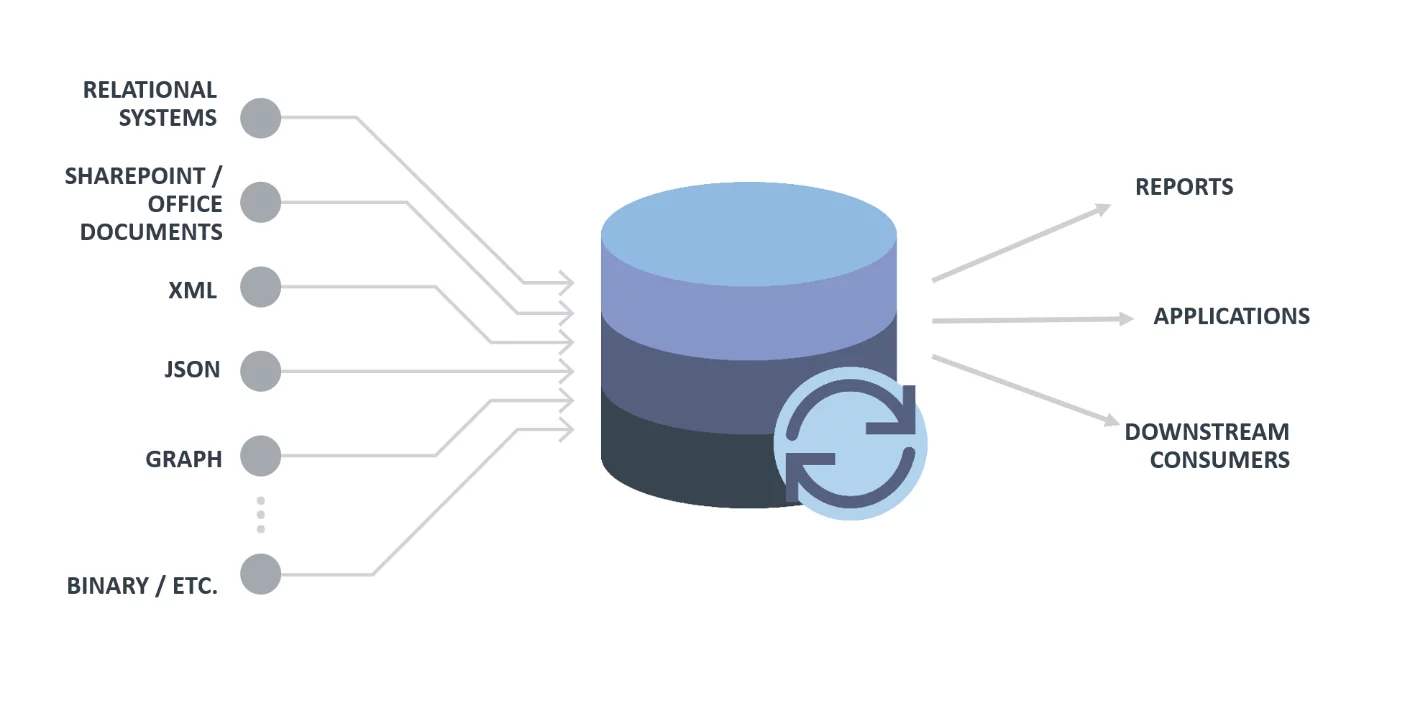
Diagrammquelle: Dataversity(1)
Warum DataHub?
Ein Hauptgrund, warum jede Organisation eine Datendrehscheibe benötigt, ist die Verbindung aller Datenkontaktpunkte und die Bereitstellung der Daten an einem zentralen Ort – technisch als Datenintegration bezeichnet. Auf einer grundlegenden Ebene bietet es Abonnementfunktionen. Wenn Sie es jedoch effektiv implementieren, gibt es zahlreiche andere Faktoren, die es zu einem bevorzugten Framework für Unternehmen machen
Sicherheit
Die meisten Unternehmen setzen Sicherheitsmaßnahmen durch, indem sie Zugriffskontrollen definieren, wer auf welche Art von Daten zugreifen kann. Beispielsweise möchten Unternehmen bestimmten Mitarbeitern keinen Zugriff auf Finanz- und Personaldaten gewähren, oder Kundendaten sollten wahrscheinlich nur auf Vertriebs- und Finanzteams beschränkt werden. Dadurch wird sichergestellt, dass Ihre Organisationshierarchie gut definiert ist, Datenzugriffspunkte gut klassifiziert sind und die Kontrollen eingerichtet sind.
Kosteneffizient
Stellen Sie sich vor, Sie haben mehrere Systeme und Sie haben diese Systeme irgendwie integriert, aber es ist nicht nahtlos. Sie haben bereits in diese individuellen Systeme investiert, und Sie haben weiter in die Integration dieser unabhängigen Systeme investiert. Da es jedoch kein vollständiger Beweis war, besteht immer noch die Herausforderung, keine Sichtbarkeit zu haben. Mit der Zeit wird diese Investition zu einer enormen Betriebsausgabe. Wenn Sie es implementieren, werden Sie unerwünschte Integrations-Touchpoints los und haben eine einzige Punkt-zu-Punkt-Integration, wodurch das Gesamtprojekt kostengünstiger wird.
Agil
Die Implementierung eines Daten-Hubs macht das gesamte Framework agil. Es beschleunigt die Integration anderer Geschäftssysteme und der Datenfluss wird schnell und nahtlos. In Abwesenheit von It wird es auch ein Szenario geben, in dem Systeme versuchen, Daten von anderen Systemen abzurufen oder abzurufen. Dann gibt es die Schaffung von Integrations-Touchpoints und Schnittstellen, was Wochen und Wochen an Implementierungszeit hinzufügt. Dadurch wird sichergestellt, dass alle Daten über eine Reihe von APIs, Zugriffsrichtlinien und einen klar definierten Abonnementprozess an einem zentralen Ort verfügbar sind.

Arten von Daten-Hubs
In diesem Abschnitt werden wir uns mit den verschiedenen Arten und den verschiedenen Arten von End-Touchpoints befassen

- Master Data Hub: Bei diesem Typ sind die Endpunkte in der Regel operative Systeme. Die Daten werden entweder im Hub oder am Endpunkt erstellt
- Application Data Hub: Auch hier ist der Datenendpunkt ein betriebsbereites System. Der Unterschied liegt in der Datenerstellung, da bei diesem Typ Daten im Hub und nicht am Endpunkt erstellt werden.
- Integration Data Hub: Bei diesem Typ erfolgt die Datenerstellung an den Endpunkten. Diese Endpunkte können unterschiedlicher Art sein, wie beispielsweise Betriebssysteme, Analysetools oder Engines oder eine beliebige externe Entität.
- Reference Data Hub: Bei diesem Typ werden die Daten je nach Geschäftsszenario entweder im Hub oder am Ende erstellt und gespeichert. Auch hier ähneln die Endpunkte den Integrationsdaten-Hubs, z. B. Betriebssystemen, Analysetools oder -Engines oder einer beliebigen externen Entität.
- Analytical Data Hub: Analytical Data Hubs speichern oder erstellen Daten nur auf Endpunkten, bei denen es sich um Betriebssysteme handelt.
Data Hub vs. Data Lake
Wenn wir uns die Data Warehouses, Data Lakes und Data Hubs ansehen, sagen die Leute, dass sie austauschbar sind. Sie unterscheiden sich jedoch in gewisser Weise und ergänzen sich normalerweise. Betrachten wir einen Vergleich zwischen dem Data Hub und dem Data Lake.
| Daten-Hub | Datensee | |
|---|---|---|
| Die primäre Nutzung erfolgt rund um betriebliche Prozesse. | Data Lake wird hauptsächlich für Analysen, maschinelles Lernen und Berichterstellung verwendet. | |
| In der Regel handelt es sich um einen strukturierten Datensatz. | Daten können strukturiert und unstrukturiert sein. | |
| Strenger Governance-Prozess zur Durchsetzung von Regeln. | Es gibt keine strikte Governance, um Regeln für den Zugriff auf Data Lakes durchzusetzen. | |
| Die Qualität der im Data Hub verwalteten Daten ist extrem hoch. | Die Qualität der in einem Data Lake gespeicherten und verwalteten Daten ist von mittlerer oder niedriger Qualität. | |
| Bietet Echtzeit-Integration mit bidirektionalem Datenfluss von/zu anderen Systemen. | Der Datenfluss ist vollständig unidirektional, was normalerweise ETL oder ELT in Batches ist. |
Abgesehen von den oben genannten Unterschieden wird Data Hub in erster Linie als Treiber von Geschäftsprozessen in Unternehmen betrachtet, während Data Lakes hauptsächlich auf Prozesse rund um maschinelles Lernen ausgerichtet sind.
Die Vorteile einer Datendrehscheibe
Inzwischen haben wir verstanden, was es ist und wie es funktioniert. Wir wissen auch, wie wichtig es ist, diese Plattform im gesamten Unternehmen zu haben. Hier sind einige wichtige Vorteile der Implementierung eines Daten-Hubs im gesamten Unternehmen.
Ein grundlegender Vorteil besteht darin, die gemeinsame Nutzung von Daten zu ermöglichen. Dies geschieht durch die Verbindung von Datenerstellern oder -quellen und Datennutzern oder -konsumenten. Diese Berührungspunkte werden auch als Endpunkte bezeichnet und interagieren mit dem Data Hub, indem sie Daten hineinschieben oder Daten abrufen. Der Hub ist ein Knotenpunkt, der den Datenfluss sichtbar macht.
Ein weiterer Vorteil besteht darin, dass es eine nahtlose und Echtzeit-Konnektivität verschiedener Geschäftssysteme herstellt. Dadurch wird sichergestellt, dass eine große Herausforderung rund um den Datenaustausch angegangen wird, insbesondere wenn Daten in einer schnelleren Reaktionszeit ausgetauscht werden müssen.
Zusammenfassend lassen sich die Vorteile in vier Kategorien einteilen
- Konsolidierung von in Silos gespeicherten Daten in einem einheitlichen System
- Flexibles und leistungsstarkes System zur Verwaltung von Arbeitsabläufen
- Bessere Sichtbarkeit und einfacher Zugriff auf Daten im gesamten Unternehmen
- Ein einheitliches System mit einer einheitlichen Oberfläche
Beispiele für Data Hub Technologien
Wie bereits erwähnt, ist ein Data Hub nicht nur eine Technologie, sondern eher eine Plattform und ein Ansatz, der von Unternehmen verfolgt wird, um die Ansicht von Daten übergreifend zu zentralisieren. Wir sehen jedoch viele Produkte, die auf dem Markt verkauft werden. Hier sind einige Beispiele, die als Technologieprodukte auf dem Markt verkauft werden.
- Google Ads
- Cloudera, Unternehmen
- Cumulocity IoT
Darüber hinaus sehen wir auch SAP als weiteres Beispiel. Das folgende Diagramm gibt eine Vorstellung von der Struktur des Data Hub und der Interaktion des SAP Data Hub mit anderen Geschäftssystemen und -technologien.
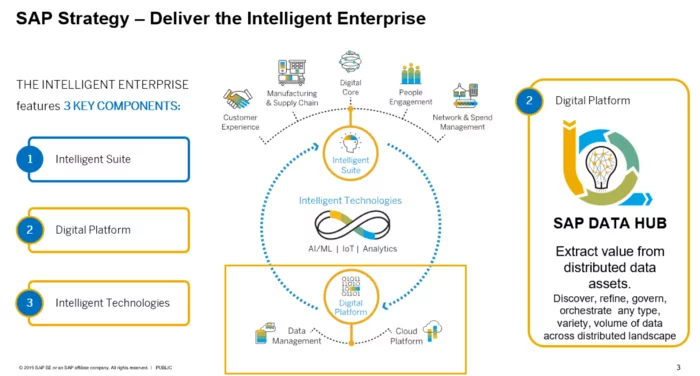
Quelle: SAP(2)
Abschließende Gedanken
Da Unternehmen heute mehrere Betriebseinheiten haben, die über verschiedene geografische Standorte verteilt sind, ist es für das Management wichtig, die Daten zu zentralisieren, die ihnen helfen, bei Bedarf zu extrahieren, um eine fundierte Entscheidung zu treffen. Ein Daten-Hub ist eher eine Plattform als nur ein Technologie-Framework.